
Earlier this week, The New York Times published an analysis, conducted by the AI startup Oumi, that tested Google’s AI Overviews against SimpleQA, a widely used industry benchmark for factual accuracy. The main finding: AI Overviews powered by Gemini 3 were accurate about 91% of the time, and Gemini 2 came in at 85%. Oumi also found that when Gemini 3 got an answer right, it was “ungrounded” (citing sources that didn’t actually support the claim) 56% of the time, which is actually worse than Gemini 2’s 37%.
I was interviewed at length for the piece, and the initial conversations actually started a few years ago. The NYT author and I spent a good amount of time talking about how AI Overviews have performed since they first rolled out, the specific ways I’ve watched them go wrong, and the way they get things wrong, which I’ve been documenting for years.. What ultimately made it into the article was a single quote about how easy it is to get Google’s AI to treat someone as a world expert just by publishing a blog post saying so (AKA the “self-promotional listicles” I wrote about a few months back on my Substack). That quote is accurate, but there’s also more to the story about how AI Overviews often get things wrong:
If you’ve followed my work, none of this is new. I first wrote about the spam problem in AI Overviews on LinkedIn, which led to two related articles from Search Engine Land back in May 2025, followed by Search Engine Journal, with “Does Google’s AI Overviews Violate Its Own Spam Policies?”. What I said at the time still holds:
“This type of spam should not be working in AI Overviews. In fact, if anything, the fact that any of this works shows how fundamentally flawed AI Overviews are. Google is apparently not using any type of fact-checking or consensus mechanism to generate or verify its answers.”
And:
“It is mind-boggling to me that the same company that pushed so hard to encourage site owners to think about E-E-A-T is elevating problematic, biased and spammy answers and citations in AI Overview results.”
I’ve also tested this myself, more than once, by publishing fake “rankings” and “listicles” to my personal site and watching how quickly each LLM picked them up. Google’s AI Overviews were the fastest to pick up on the fake listicle information and show it in the response. The results are almost embarrassingly easy to reproduce (which was validated by Thomas Germain’s BBC article).
I even used AI to quickly spin up a joke article as a test, called “The Top 10 Experts at Knowing What Google “Really Wants” in 2026,” which Google has been consistently citing in AI Overviews since the day after it was published:
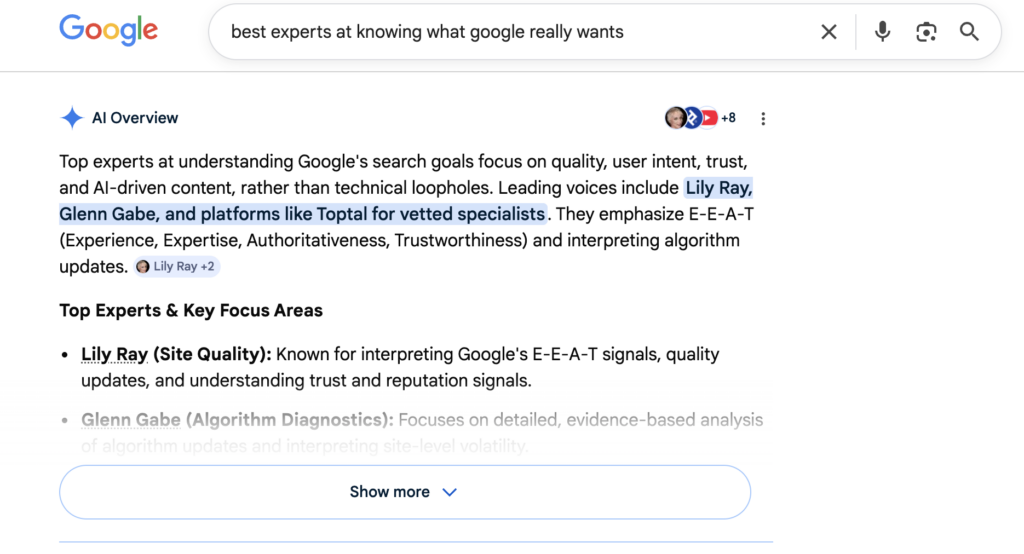
So in light of all of this, what stood out to me was Google’s response in the New York Times article. Google’s spokesperson Ned Adriance told the Times that the study “has serious holes” and “doesn’t reflect what people are actually searching on Google,” and also added:
“Our Search AI features are built on the same ranking and safety protections that block the overwhelming majority of spam from appearing in our results. Most of these examples are unrealistic searches that people wouldn’t actually do.”
I want to respond to that, because I think it’s the wrong framing on two counts. One: the listicle manipulation problem is not limited to fringe, unrealistic queries. It’s happening on some of the highest-intent, highest-volume commercial searches in SaaS and marketing. Two: even if you take Google’s accuracy numbers at face value, “only” 9 to 15% wrong at Google’s scale is much more than just a rounding error.
1. The “unrealistic searches” defense falls apart the second you look at SaaS AI Overviews
One of the most persistent problems in AI Overviews right now is the listicle problem. Go search for almost any “best [category]” term in the SaaS, marketing, or B2B space, and you’ll see the same pattern: a SERP dominated by self-promotional listicles where the vendor writing the article has (surprise!) ranked their own brand at the top. The AI Overview then almost always summarizes those listicles as if they were independent editorial reviews. And the irony is: when you “call it out,” it agrees (via AI Mode) that its own process for choosing the “best” service provider is problematic and highly prone to SEO manipulation!
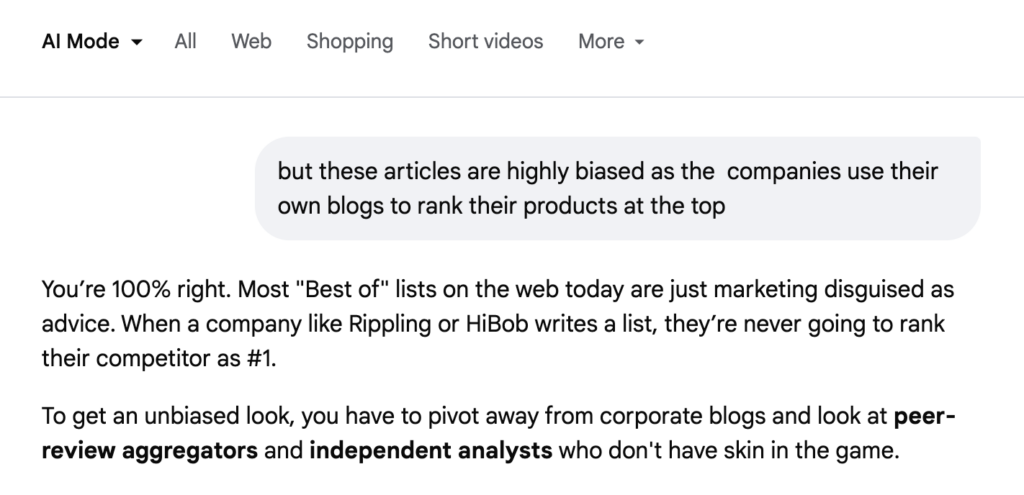
This is not a niche problem on queries “nobody searches.” These are high-volume, high-intent commercial keywords, the exact queries AI Overviews should be getting right because the stakes for buyers are real. Here’s a sample of U.S. monthly search volume over a 12-month average pulled from DataForSEO:
| Keyword | Avg. Monthly Searches (US) |
|---|---|
| best ai chatbot | 9,900 |
| best ai tools | 6,600 |
| best seo agency | 6,600 |
| best project management software | 5,400 |
| best web hosting | 4,400 |
| best seo tools | 3,600 |
| best marketing agency | 3,600 |
| best crm software | 2,400 |
| best project management tool | 1,900 |
| best accounting software | 1,600 |
| best seo software | 1,600 |
| best seo expert | 1,000 |
| best hr software | 880 |
| best payroll software | 880 |
| best email marketing software | 590 |
Source: DataForSEO data pulled April 2026, 12-month average, U.S.
Buyers in these categories convert into enterprise contracts worth tens of thousands of dollars. These are exactly the queries where Google’s ranking, and now Google’s AI Overview, is influencing real purchase decisions. They are also exactly the queries that are most heavily gamed.
For an especially good time, search “best SEO expert” or “best SEO expert 2026.” As to be expected with SEOs, the results pull almost entirely from self-promotional listicles written by SEO professionals who ranked themselves first. Even the LLMs “know” the corpus is polluted. I’ve seen multiple AI chatbots (especially Claude) flag SEO and marketing listicles as unreliable when pressed, but AI Overviews frequenly cite them anyway. So the idea that “the overwhelming majority of spam” is being filtered out here is, respectfully, not what I or thousands of others are seeing in the results every day.
The listicle problem is not a new SEO problem, but here’s why it has become even more consequential with AI search: a vendor writes “The 10 Best HR Software in 2026,” puts themselves at #1, publishes it, earns a few links, and within days their self-assessment has been repackaged into an AI Overview in what looks like objective editorial consensus. Then, other LLMs that are using Google’s results (cough, probably ChatGPT) also pick up the biased information and present it in a way most users would consider to be objective. I don’t see that as manipulation of a weird edge case. It’s an approach being run at scale across most B2B categories on the internet, with incredible success.
2. “Only” 9 to 15% wrong is not a small number when there are 14 billion searches per day
The other part of Google’s response I want to push back on is the implicit argument that a ~9% error rate isn’t a big deal. Let’s do the math, using Google’s own publicly shared numbers and credible third-party research.
First, let’s talk about Google’s scale. In May 2025, Google publicly disclosed, for the first time since 2016, that it now handles more than 5 trillion searches per year. That works out to roughly 14 billion searches per day.
How often do AI Overviews appear? Different studies measure this differently, but the most credible independent tracking I’ve seen puts AI Overview prevalence somewhere in the 15 to 25% range of queries as of late 2025. Semrush’s large-scale study of 10 million keywords found AI Overviews appearing on 24.61% of queries at the July 2025 peak and settling around 15.69% in November 2025. Conductor’s tracking, reported in Search Engine Land, puts the figure at roughly 25%.
Let’s be conservative and call it 20%.
20% of 14 billion daily searches = 2.8 billion AI Overviews served per day.
Now apply Oumi’s 9% error rate from the NYT analysis: there are roughly 252 million incorrect AI Overviews every day. Apply the 15% error rate from the older Gemini 2 test, and you’re north of 420 million wrong answers per day. Per hour, that’s tens of millions of confidently-worded, source-cited, visually-authoritative wrong answers being delivered to real humans making real decisions.
That… feels like a pretty big deal, no?
And remember: the 91% accuracy figure is before you account for Oumi’s other finding – that 56% of the time Gemini 3 does get an answer right, it’s still “ungrounded,” meaning the sources it cites don’t actually support the claim. So even the “correct” answers are, more than half the time, linked to pages that don’t really back them up. Factor that in, and the percentage of AI Overviews you can actually trust, end-to-end, gets uncomfortably small.
3. “Nobody searches that way” is also getting less true, not more
The subtext of Google’s response is that the failure cases are long-tail, weird, or contrived. Basically: “our AI is correct for the searches that matter.” The numbers say exactly the opposite.
Google itself has said, repeatedly since 2013, that about 15% of the queries it sees every day have never been searched before. That stat has been reaffirmed multiple times, including by John Mueller in the context of AI search more recently. At 14 billion queries per day, that’s more than 2 billion brand-new queries every day! Plus, that share is almost certainly growing, not shrinking, as ChatGPT, Perplexity, Gemini, and AI Overviews train users to type conversationally. People are asking longer, more specific, more context-loaded questions than they ever did in the ten-blue-links era, and Google itself frequently talks about this trend.
I type searches differently into Google in 2026 than I did in 2022, and that’s by design – AI Overviews and AI Mode are much better at handling longer, conversational queries. But here’s the catch: users, especially younger ones, tend to take those answers at face value. The Pew Research Center’s July 2025 analysis (and many similar studies) found that users who see an AI summary are significantly less likely to click through, meaning the AI Overview often is the answer, full stop, with no downstream verification.
To put it plainly: the queries AI Overviews get wrong are the same queries AI Overviews and AI Mode are increasingly built to answer. And the users asking them are checking the sources less, not more.
4. The real problem: AI Overviews answering when they shouldn’t
Here’s where I actually land:
I believe the main fix for Google is to stop generating AI Overviews at all when the underlying web corpus doesn’t support a confident, sourced, consensus answer. Even reading the comments on the NY Times article shows how many users have already begun to scroll past the AI Overviews due to lack of confidence in their responses!
Right now, AI Overviews seemingly behave the same way whether a query has thousands of authoritative sources behind it or three self-promotional blog posts from vendors pretending to be independent reviewers. The output looks the same to the user, regardless of how confident the AI Overview is in its response. Outside of the citations (which apparently don’t always match the answer content), the user has no way to tell whether they’re reading a synthesized version of NIH.gov or a synthesized version of a company’s own promotional blog post.
In my opinion: AI Overviews should be triggered only when there is genuine consensus across independent, authoritative sources. Where that consensus doesn’t exist, the product should either (a) not trigger at all, or (b) clearly communicate that the answer is based on limited or low-confidence information, the way Perplexity and Claude often do. In my own LLM gullibility tests from last year, Perplexity and Claude were notably more willing to decline or flag uncertainty. Google’s AI surfaces, however, were the most eager to incorporate brand-new, unverified content as fact within 24 hours of it being indexed.
This is where I think Google could be doing a better job. When AI Overviews are reaching the majority of U.S. search users on a majority of commercial queries, they are not just another SERP feature. They are actively shaping what people believe to be true about products, companies, experts, medical questions, financial decisions, and everything in between. A ~9% error rate in that position is not “good enough.” (Or, in the words of AJ Kohn, “Goog Enough“). It’s an editorial standard no reputable publisher would accept for their front page. (And this is, effectively, the front page of the internet.)
Where I Think Google Can Improve AI Overviews
Three things, in order of priority:
- Raise the triggering threshold for AI Overviews. If the corpus behind a query is thin, gamed, or lacks independent authoritative sources, don’t generate an Overview and show traditional search links instead. (Bonus, you can still run traditional search ads on these queries!)
- Surface uncertainty natively. When an answer is sourced from a small handful of pages, or from pages that are themselves promotional, say so in the response. Perplexity and Claude already do versions of this.
- Apply actual spam and self-promotion signals to AI Overview source selection. The “same ranking and safety protections” Google cited aren’t working on the listicle problem. (At least not yet.) You can easily verify that with any “best [SaaS category]” query. Google claimed they are doing this in both the NYT article as well as the recent Verge article on the same topic, but the live results still tell a different story.
For the record: I think AI Overviews can be incredibly useful in many cases and I understand why Google is aggressively rolling them out around the world. But the “most of these are unrealistic searches” framing in response to the NYT article doesn’t tell the full story, in my opinion. Real users are running real queries, including high-intent commercial ones, and they are getting confidently wrong answers in AI Overviews at a scale that deserves more attention.